Adaptive best subset selection for robust principal component analysis
Source:R/abessrpca.R
abessrpca.RdDecompose a matrix into the summation of low-rank matrix and sparse matrix via the best subset selection approach
abessrpca(
x,
rank,
support.size = NULL,
tune.path = c("sequence", "gsection"),
gs.range = NULL,
tune.type = c("gic", "aic", "bic", "ebic"),
ic.scale = 1,
lambda = 0,
always.include = NULL,
group.index = NULL,
c.max = NULL,
splicing.type = 2,
max.splicing.iter = 1,
warm.start = TRUE,
important.search = NULL,
max.newton.iter = 1,
newton.thresh = 0.001,
num.threads = 0,
seed = 1,
...
)Arguments
- x
A matrix object.
- rank
A positive integer value specify the rank of the low-rank matrix.
- support.size
An integer vector representing the alternative support sizes. Only used for
tune.path = "sequence". Strongly suggest its minimum value larger thanmin(dim(x)).- tune.path
The method to be used to select the optimal support size. For
tune.path = "sequence", we solve the best subset selection problem for each size insupport.size. Fortune.path = "gsection", we solve the best subset selection problem with support size ranged ings.range, where the specific support size to be considered is determined by golden section.- gs.range
A integer vector with two elements. The first element is the minimum model size considered by golden-section, the later one is the maximum one. Default is
gs.range = c(1, min(n, round(n/(log(log(n))log(p))))).- tune.type
The type of criterion for choosing the support size. Available options are "gic", "ebic", "bic" and "aic". Default is "gic".
- ic.scale
A non-negative value used for multiplying the penalty term in information criterion. Default:
ic.scale = 1.- lambda
A single lambda value for regularized best subset selection. Default is 0.
- always.include
An integer vector containing the indexes of variables that should always be included in the model.
- group.index
A vector of integers indicating the which group each variable is in. For variables in the same group, they should be located in adjacent columns of
xand their corresponding index ingroup.indexshould be the same. Denote the first group as1, the second2, etc. If you do not fit a model with a group structure, please setgroup.index = NULL(the default).- c.max
an integer splicing size. Default is:
c.max = 2.- splicing.type
Optional type for splicing. If
splicing.type = 1, the number of variables to be spliced isc.max, ...,1; ifsplicing.type = 2, the number of variables to be spliced isc.max,c.max/2, ...,1. (Default:splicing.type = 2.)- max.splicing.iter
The maximum number of performing splicing algorithm. In most of the case, only a few times of splicing iteration can guarantee the convergence. Default is
max.splicing.iter = 20.- warm.start
Whether to use the last solution as a warm start. Default is
warm.start = TRUE.- important.search
An integer number indicating the number of important variables to be splicing. When
important.search\(\ll\)pvariables, it would greatly reduce runtimes. Default:important.search = 128.- max.newton.iter
a integer giving the maximal number of Newton's iteration iterations. Default is
max.newton.iter = 10ifnewton = "exact", andmax.newton.iter = 60ifnewton = "approx".- newton.thresh
a numeric value for controlling positive convergence tolerance. The Newton's iterations converge when \(|dev - dev_{old}|/(|dev| + 0.1)<\)
newton.thresh.- num.threads
An integer decide the number of threads to be concurrently used for cross-validation (i.e.,
tune.type = "cv"). Ifnum.threads = 0, then all of available cores will be used. Default:num.threads = 0.- seed
Seed to be used to divide the sample into cross-validation folds. Default is
seed = 1.- ...
further arguments to be passed to or from methods.
Value
A S3 abessrpca class object, which is a list with the following components:
- S
A list with
length(support.size)elements, each of which is a sparse matrix estimation;- L
The low rank matrix estimation.
- nobs
The number of sample used for training.
- nvars
The number of variables used for training.
- rank
The rank of matrix
L.- loss
The loss of objective function.
- tune.value
A value of tuning criterion of length
length(support.size).- support.size
The actual support.size values used. Note that it is not necessary the same as the input if the later have non-integer values or duplicated values.
- tune.type
The criterion type for tuning parameters.
- call
The original call to
abessrpca.
Details
Adaptive best subset selection for robust principal component analysis aim to find two latent matrices \(L\) and \(S\) such that the original matrix \(X\) can be appropriately approximated: $$x = L + S + N,$$ where \(L\) is a low-rank matrix, \(S\) is a sparse matrix, \(N\) is a dense noise matrix. Generic splicing technique can be employed to solve this problem by iteratively improve the quality of the estimation of \(S\).
For a given support set \(\Omega\), the optimization problem:
$$\min_S \| x - L - S\|_F^2 \;\;{\rm s.t.}\;\; S_{ij} = 0 {\rm for } (i, j) \in \Omega^c,$$
still a non-convex optimization problem. We use the hard-impute algorithm proposed in one of the reference to solve this problem.
The hard-impute algorithm is an iterative algorithm, people can set max.newton.iter and newton.thresh to
control the solution precision of the optimization problem.
(Here, the name of the two parameters are somehow abused to make the parameters cross functions have an unified name.)
According to our experiments,
we assign properly parameters to the two parameter as the default such that the precision and runtime are well balanced,
we suggest users keep the default values unchanged.
Note
Some parameters not described in the Details Section is explained in the document for abess
because the meaning of these parameters are very similar.
At present, \(l_2\) regularization and group selection are not support,
and thus, set lambda and group.index have no influence on the output.
This feature will coming soon.
References
A polynomial algorithm for best-subset selection problem. Junxian Zhu, Canhong Wen, Jin Zhu, Heping Zhang, Xueqin Wang. Proceedings of the National Academy of Sciences Dec 2020, 117 (52) 33117-33123; doi:10.1073/pnas.2014241117
Emmanuel J. Candès, Xiaodong Li, Yi Ma, and John Wright. 2011. Robust principal component analysis? Journal of the ACM. 58, 3, Article 11 (May 2011), 37 pages. doi:10.1145/1970392.1970395
Mazumder, Rahul, Trevor Hastie, and Robert Tibshirani. Spectral regularization algorithms for learning large incomplete matrices. The Journal of Machine Learning Research 11 (2010): 2287-2322.
Examples
# \donttest{
library(abess)
Sys.setenv("OMP_THREAD_LIMIT" = 2)
n <- 30
p <- 30
true_S_size <- 60
true_L_rank <- 2
dataset <- generate.matrix(n, p, support.size = true_S_size, rank = true_L_rank)
res <- abessrpca(dataset[["x"]], rank = true_L_rank, support.size = 50:70)
print(res)
#> Call:
#> abessrpca(x = dataset[["x"]], rank = true_L_rank, support.size = 50:70)
#>
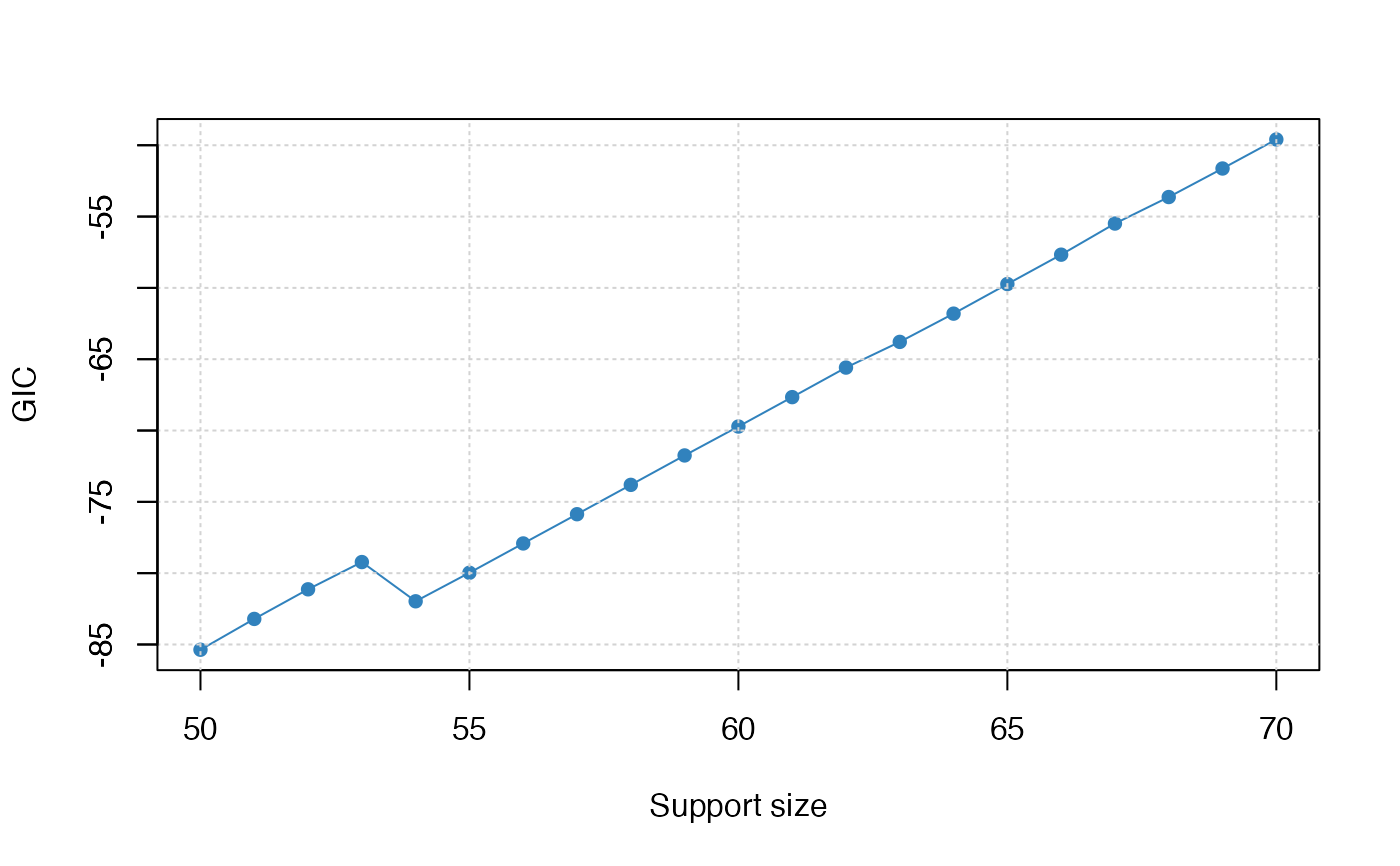
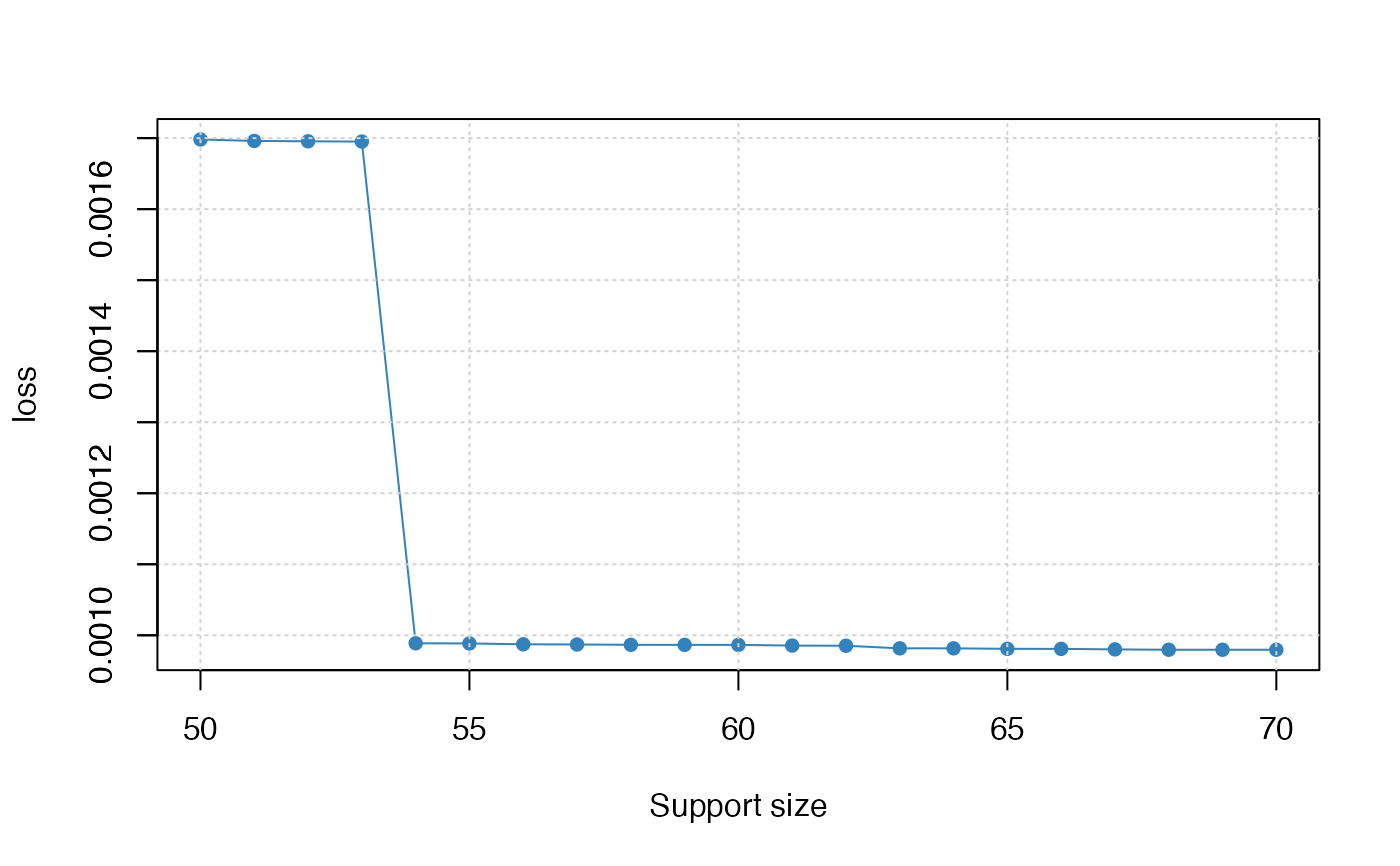
#> support.size loss gic
#> 1 50 0.0016981355 -85.36887
#> 2 51 0.0016960154 -83.20781
#> 3 52 0.0016955336 -81.13205
#> 4 53 0.0016951360 -79.22125
#> 5 54 0.0009887097 -81.97160
#> 6 55 0.0009885436 -79.97169
#> 7 56 0.0009873386 -77.91668
#> 8 57 0.0009870779 -75.86674
#> 9 58 0.0009865842 -73.80921
#> 10 59 0.0009865090 -71.74674
#> 11 60 0.0009864850 -69.71969
#> 12 61 0.0009855249 -67.65866
#> 13 62 0.0009852846 -65.58680
#> 14 63 0.0009816356 -63.78628
#> 15 64 0.0009816191 -61.80540
#> 16 65 0.0009809479 -59.73263
#> 17 66 0.0009808753 -57.67144
#> 18 67 0.0009801463 -55.48928
#> 19 68 0.0009796508 -53.63124
#> 20 69 0.0009796518 -51.63064
#> 21 70 0.0009796469 -49.59384
coef(res)
#> 30 x 30 sparse Matrix of class "dgCMatrix"
#>
#> [1,] . . . . . . .
#> [2,] . . . . . . .
#> [3,] . 0.9819563 . . . . .
#> [4,] . . . . . . .
#> [5,] -0.9254326 . . . . . 1.097291
#> [6,] . . . . . . .
#> [7,] . . . . . . .
#> [8,] . . . . . . .
#> [9,] . . . . . . .
#> [10,] -1.0362835 . . . . . .
#> [11,] . . . . 0.95168769 . .
#> [12,] . . . . . 1.0091387 .
#> [13,] . . . . . . .
#> [14,] . . . . . . .
#> [15,] -0.9263183 . . . . . .
#> [16,] . . . . . . .
#> [17,] 0.3664819 . . -0.8691699 . . .
#> [18,] . -0.9790917 . . . . .
#> [19,] . . . . . . .
#> [20,] . . . . 0.04288605 0.9726483 -1.036357
#> [21,] . . . . . . .
#> [22,] . . . . . . .
#> [23,] . . . . . . .
#> [24,] . . . . . . .
#> [25,] . . . 1.0224565 . . .
#> [26,] . . . . . . .
#> [27,] . . . . -1.02347450 . .
#> [28,] . . . . . . .
#> [29,] . . . . . . .
#> [30,] . . . . . . .
#>
#> [1,] . . . . . . .
#> [2,] . . . -1.002852 . . .
#> [3,] . . . . 0.9476839 0.9887129 .
#> [4,] . . . . . . .
#> [5,] . 0.9945920 -0.9728291 . . . .
#> [6,] . . . . . . .
#> [7,] . . . . . . .
#> [8,] . . . . . . .
#> [9,] . . . . . . .
#> [10,] . . . . . . .
#> [11,] . 0.9787635 . . . . .
#> [12,] . . . . . . .
#> [13,] . . . . . . .
#> [14,] . . . . . . .
#> [15,] . . . . . . .
#> [16,] . . . . . . .
#> [17,] . . . . . . .
#> [18,] . . . . . . .
#> [19,] 0.9660002 . . . . 1.0139147 .
#> [20,] . . . . . . .
#> [21,] . . . . . . 1.0140973
#> [22,] . . . . . . -0.9739175
#> [23,] . . . . . . .
#> [24,] . . . . . . .
#> [25,] . . . . . . .
#> [26,] . . . . . . .
#> [27,] . . . . . . .
#> [28,] . . . . . . .
#> [29,] . . . . . . .
#> [30,] . . . . . . .
#>
#> [1,] 1.0043963 -0.9341438 . . . . . .
#> [2,] . . . . . . . .
#> [3,] . . . . . . . .
#> [4,] . . . . . . . .
#> [5,] . . . . . . . .
#> [6,] . . . -1.047745 . . . .
#> [7,] . . . . . . . .
#> [8,] . . . . . . . .
#> [9,] . . . . . . . .
#> [10,] . . . . . . . .
#> [11,] . . . . . . . .
#> [12,] . . . . -1.008001 . . .
#> [13,] . . . . . . . .
#> [14,] . . . . . . . .
#> [15,] . . . . . . 0.9785829 .
#> [16,] . . . . . . -0.1625570 .
#> [17,] . . . . . . 0.9418696 .
#> [18,] . . . . . . . .
#> [19,] . . . . . . . 0.9755463
#> [20,] . . . . . 1.001471 . .
#> [21,] . . . . . . . .
#> [22,] -0.9962464 . . . . . . .
#> [23,] . . . . . . . .
#> [24,] . . . . . . . .
#> [25,] . . . . . . . .
#> [26,] . -0.9198632 . . . . . .
#> [27,] . . . 0.985852 . . . .
#> [28,] . . . . . . . .
#> [29,] . -0.9683991 . . . . . .
#> [30,] . . . . . . . .
#>
#> [1,] . . . . . . .
#> [2,] . . . . . . .
#> [3,] . . . . . . .
#> [4,] . . . . 1.074903 . .
#> [5,] . . . . . . .
#> [6,] . . . . . . .
#> [7,] . . . . . . .
#> [8,] . -1.031791 . . . . .
#> [9,] . . . . . . .
#> [10,] . 1.003335 . . . . .
#> [11,] . . . . . . .
#> [12,] . . . -1.003959 . 1.000823 .
#> [13,] . . . . . . .
#> [14,] -0.9163911 . . . . . .
#> [15,] . . . . . . .
#> [16,] . . . . . . .
#> [17,] . . . . . . .
#> [18,] . . . . . . -1.0160861
#> [19,] . . . . . . .
#> [20,] . . . . . . .
#> [21,] . . 1.031148 . . -1.010667 .
#> [22,] . . . . . . .
#> [23,] . . . . . . .
#> [24,] . . . . . . .
#> [25,] . . . . . . .
#> [26,] . . . . . . .
#> [27,] . . . . . . -0.9951534
#> [28,] . . . . . . .
#> [29,] . . . . . . .
#> [30,] . . . . . . .
#>
#> [1,] .
#> [2,] .
#> [3,] .
#> [4,] .
#> [5,] .
#> [6,] .
#> [7,] .
#> [8,] .
#> [9,] .
#> [10,] .
#> [11,] .
#> [12,] .
#> [13,] -1.006640
#> [14,] .
#> [15,] .
#> [16,] .
#> [17,] .
#> [18,] .
#> [19,] .
#> [20,] .
#> [21,] .
#> [22,] .
#> [23,] .
#> [24,] .
#> [25,] .
#> [26,] .
#> [27,] .
#> [28,] 1.009848
#> [29,] .
#> [30,] .
plot(res, type = "tune")
 plot(res, type = "loss")
plot(res, type = "loss")
 plot(res, type = "S")
plot(res, type = "S")
 # }
# }